 デジタル
デジタル
 ゲーム・ホビー
ゲーム・ホビー
 システム・通信
システム・通信
 観光・レジャー
観光・レジャー
 エンタメ
エンタメ
 スポーツ・アウトドア
スポーツ・アウトドア
 自動車・バイク
自動車・バイク
 ホーム
ホーム
 ファッション
ファッション
 食・グルメ
食・グルメ
 美容・健康
美容・健康
 ライフスタイル
ライフスタイル
 金融・保険
金融・保険
 広告・宣伝
広告・宣伝
 交通・物流
交通・物流
 エネルギー・環境
エネルギー・環境
 自治体など
自治体など
ブラウザだけで使える無料統計ソフト Reactive stat の Long Format(縦長データ)とWide Format(横広データ)の相互変換機能をバージョンアップ
エミュイン合同会社
2024.12.04 19:02
柔軟なカラム設定と強力な変換オプションを搭載、研究現場のニーズに対応しました
ブラウザベースの無料統計解析ソフト「Reactive stat」に、高度なデータ形式変換機能が追加されました。新機能では、Long Format(縦長データ)とWide Format(横広データ)の相互変換において、複数のID列の組み合わせや柔軟な値カラムの設定、さらには重複データや欠損値の詳細な処理オプションを提供します。複数カラムの同時変換や自動ID生成など、実務での多様なニーズに応える機能を備えています。変換後のデータは即座に統計解析に利用できるほか、CSV形式でのダウンロードも可能です。Rの信頼性の高い統計エンジンとAIによる結果解説を特徴とする本ソフトウェアは、この機能追加により、より幅広い統計解析シーンでの活用が期待されます。


研究者の皆様から「データの形式変換に手間がかかってしまう」「どのように整理すれば良いかわからない」というお声を多くいただいてきました。
今回の機能追加は、そうした皆様の悩みに応えるべく開発したものです。それでは、新機能の詳細についてご説明させていただきます。

柔軟なデータIDの組み合わせ機能
まず、データのIDの扱いについて、大幅な機能強化を行いました。
研究の現場では、「被験者ID」と「グループID」を組み合わせて使用するケースが多いことから、複数のID列を自由に組み合わせられるようにしました。
IDを指定しない場合は自動的に行番号が振られる機能も追加し、急いでデータを確認したい場合にも対応できるようにしています。また、欠損値のあるデータの扱いも、除外するかそのまま残すか選択できるようにしました。
重複する値の処理機能
値の処理に関しても、実務でよく直面する課題に対応できるよう工夫を重ねました。
例えば、同じIDに複数の測定値がある場合、その処理方法を10種類から選べるようにしています。
単純に最初の値を使うだけでなく、平均値や中央値の計算、さらには時系列データでよく使う最小値・最大値の選択なども可能ですし、カンマ区切りで全ての値を保持することもできます。
データの特性に応じて最適な方法を選んでいただけます。
分類データの効率的な管理
分類データの扱いについても、研究現場の実態に即して機能を実装しました。
複数の条件を組み合わせた分析がしたい場合や、階層構造のあるデータを扱う場合など、様々なケースに対応できます。
変換内容に応じてわかりやすいカラム名が適切に自動生成されます。
変換結果の「見える化」にこだわりました
重複データがある場合は警告を表示し、どのようなデータが重複しているのかを確認できるようにしています。
これにより、想定外の誤変換による誤りを防ぎ、データの整合性を保ちながら、安心して解析を進めていただけます。
使いやすい出力オプション
変換したデータはすぐに統計解析に使えるほか、CSVファイルとしてダウンロードすることも可能です。
想定される活用シーン
具体的な活用シーンとしては、以下のようなケースを想定しています:
- 経時データの分析:治療前後の比較や、複数回の測定データの整理
- クロス集計データの作成:複数の要因の組み合わせによる分析
- 実験データの整理:異なる条件下での測定結果の比較
- 階層データの処理:学校・クラス・生徒といった入れ子構造のデータ分析
- 反復測定データの整形:同一被験者の複数回測定データの処理
- マルチレベル分析:個人レベルと集団レベルの要因を含む分析
Long format と Wide Format

具体例 (数学と英語のテスト結果)
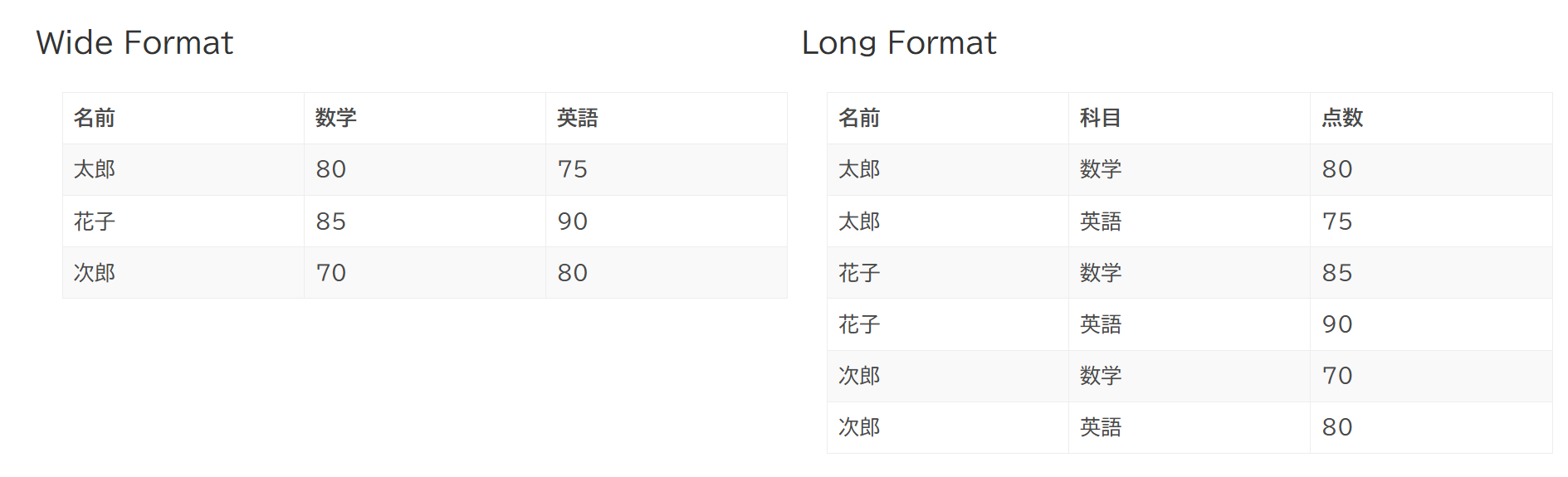
Wide Format が適切な解析手法の例
- 対応のある群間検定 (対応のあるt検定、Wilcoxon の符号順位検定 など)
- 例: 同じ生徒の数学の点数を、ある教育方法の実施前と後で比較する。
- 理由: 各生徒の前後の測定値が同じ行にあり、個人内の変化を直接比較しやすい。
- 多変量解析
- ANOVA、ロジスティック回帰、ANCOVA、重回帰分析、多変量分析、主成分分析 (PCA)、因子分析 など。
- 例:
- ANOVA (多元配置分散分析): 学年、性別、学習方法が試験成績に与える影響を同時に分析する。
- ロジスティック回帰モデル: 生徒の属性 (年齢、学習時間、出席率) から合格/不合格を予測する。など
- 理由:
- 複数の変数間の関係を同時に分析し、交互作用や複雑なパターンを検出できる。
Long Format が適切な解析手法の例
- 対応のない群間検定 (t検定、Mann-Whitney U検定 など)
- 例: 異なる2つのクラスの数学の点数を比較する。
- 理由: 各観測値が独立した行にあり、群 (クラス) 間の比較がしやすい。
- 混合効果モデル
- 例: 生徒の成績に対する、教師の影響と生徒個人の特性の影響を分離して分析する。
- 理由: 個人内変動と個人間変動を同時に扱えるため。
Long format から Wide Format に変換

カラムの設定 IDカラムの設定
- 「ID のカラム」セクションで、個体や参加者を識別するためのカラムを選択します
- 複数のカラムを選択可能です (例: 被験者ID + グループID)
- オプション設定
- 「IDのいずれかが欠損値の場合はデータを除外する」にチェックを入れると、IDに欠損がある行を除外します
- ID列に半角スペースが含まれる場合、「ID列の半角スペースを “_” に置き換える」オプションが表示されます
- 複数のID列を選択した場合:
- 新しいIDカラムが自動生成されます
- ID列の区切り文字を選択できます (アンダースコア、ハイフン、カンマ、空白)
値のカラムの設定
- 「値のカラム」セクションで、分析対象となる数値が含まれるカラムを選択します
- 一つのカラムのみ選択可能です
分類カラムの設定
- 「分類カラム」セクションで、Wide Format の列見出しとなるカラムを選択します
- 複数のカラムを選択可能です
- オプション設定:
- 生成されるカラム名に半角スペースが含まれる場合、「生成されるカラム名の半角スペースを “_” に置き換える」オプションが表示されます
- 生成されるカラム名に、分類カラムの値だけでなく、分類カラム名を接頭辞として付与することができます
未指定カラム
上記のいずれにも指定されなかったカラムは、ワイドフォーマットのデータのカラムに移されます。
重複データの処理
Long format では、同一被験者のデータが複数行にわたって示されますが、例えば性別などのカラムもある場合には、その値が繰り返し出現します。 この場合は話は単純です。
しかし、体重や年齢は、時系列データの場合には途中で変わることがあります。 そのようなデータを Wide format にする場合には、代表値を選ぶ必要があります。 試験開始時・終了時、中央値など、状況に応じて選択してください。
指定カラムの重複データ処理
同じID・条件の組み合わせに複数の値が存在する場合、 全ての値を “,” で接続・ 重複を取り除いた値を “,” で接続・ 最初の値のみ・ 最後の値のみ・ 平均値・ 中央値・ 最小値・ 最大値・ 合計 から処理方法を選択できます。
未指定カラムの重複データ処理
ID、値、分類のいずれにも指定されなかったカラムについても、同様の処理方法を選択できます。
Wide format から Long Format に変換

カラムの設定
IDカラムの設定
- 「ID のカラム」セクションで、個体や参加者を識別するためのカラムを選択します
- 複数のカラムを選択可能です (例: 被験者ID + グループID)
- ID列を指定しない場合は、行番号が自動的に振られた ID カラムが生成されます
- オプション設定
- 「IDのいずれかが欠損値の場合はデータを除外する」にチェックを入れると、IDに欠損がある行を除外します
- 複数のID列を選択した場合:
- 「新規に ID カラムを作成する」オプションで、ID列を組み合わせた新しいカラムを生成できます
- ID列の区切り文字を選択できます (アンダースコア、ハイフン、カンマ、空白)
値のカラムの設定
- 「値のカラム」セクションで、Long format に変換する対象となるカラムを選択します
- 複数のカラムを選択可能です
- 選択したカラムは変数名カラムと値カラムに分割されます
- 変数名カラム: 元のカラム名が値として入ります
- 値カラム: 元のカラムの値が入ります
- カラム名の設定
- 変数カラム名: デフォルトは「変数」
- 値カラム名: デフォルトは「値」
未指定カラムの設定
- ID列や値のカラムとして指定されなかったカラムは、デフォルトでそのまま保持されます
- 「指定されなかったカラムのデータを付与する」のチェックを外すと、これらのカラムは除外されます
データの処理
重複IDの処理: 複数のID列を指定した場合、ID列の組み合わせに重複があると警告が表示されます。
- 重複がある場合:
- 重複している組み合わせと該当する行番号が表示されます
- 「続行」または「中止」を選択できます
- 重複を含むデータの処理:
- 続行を選択した場合: すべてのデータが変換されます
- 中止を選択した場合: 変換が中止されます
欠損値の処理
ID列に欠損値がある場合の処理を選択できます。
- 「IDのいずれかが欠損値の場合はデータを除外する」オプション:
- チェックあり: 欠損値を含む行は除外されます
- チェックなし: 欠損値を含む行もそのまま変換されます
- 欠損値の判定:
- null または undefined の値
- データテーブルの欠損値設定で指定された値
- 空白を欠損値として扱う設定が有効な場合は空白文字
出力データ
変換後のデータは以下の形式で出力されます:
- ID列 (単数または複数)
- 変数名カラム (元のカラム名)
- 値カラム (元のカラムの値)
- その他の未指定カラム (オプション)
データの利用
変換後のデータは以下の方法で利用できます:
- 「変換後のデータを統計解析に利用」ボタン: データを統計解析用に設定
- 「変換後のデータを CSV でダウンロード」ボタン: CSV 形式でダウンロード
Reactive stat について
~ブラウザだけで使える無料統計ソフト~ 信頼性の高い R で統計解析し、その結果を AI が解説します!
ブラウザとデータファイルがあれば、すぐに解析できます
- マニュアル本は要りません。
- すべての統計手法のページには、利用に必要な解説が載っていますし、必要な情報へのリンクも用意してあります。
- PCにソフトウェアをインストールする必要はありません。
- 信頼性の高い R での結果が得られます。
- ウェブアプリで結果を得たあとに、そのデータを外部の R サーバーに送信し、その実行結果を得ることができます。
- 外部の R サーバーに送信されるデータは、セキュリティを考慮し、数値計算に必要な最小限のセットとしています。また、送信前に内容を確認できます。自動的に送信されることはありません。
- 常に最新バージョンのRを利用できます。
- 結果がリアルタイムに反映されるウェブアプリですので、統計解析に不慣れな場合でも試行錯誤が容易です。
- データの内容を常に把握しながら作業が行えるように工夫してありますので、どうしたらいいかわからない、という状況に陥ることがありません。
- 出力されるグラフはインタラクティブな高機能なものです。
- データファイルを読み込んで利用できます。
- CSV 形式データファイルおよびエクセルファイルに対応
- データファイルはブラウザ内部に読み込まれるだけで外部には送信されませんので、セキュリティの問題はありません。
- 日本語のデータファイルを扱うことができます
- 海外製のアプリですと、カラム名が日本語だと受け付けられないなどの制約がしばしばありますが、Reactive stat にはそのような制限はありません。

共用PCやタブレットでも
ソフトをインストールできない共用のPCや、iPad などタブレットでも実行可能です。
モバイルデバイスの場合は、 Google Drive, One Drive などのクラウドストレージからファイルを直接読み込むことができます。
読み込んだデータファイルの内容がそのままクラウドに送信されることはありませんので、個人情報を含むデータでも安心して解析できます。 共用PCの場合は、ログアウトすればすべて消去されますので安心です。
なお、R での解析やその結果を AI に解説させる機能では、クラウドに最小限のデータを送信しますが、統計解析に必要最小限のデータであり、個人情報が送信されることはなく、また、送信前にその内容を確認する手順になっていますので安心です。
スマートフォンでも
スマートフォンでも使えるように画面設計してあります!
最終的な統計解析を行うことを想定しているわけではなく、統計に不慣れなユーザーに手軽に親しんでいただくことが目的です。 専用のサンプルデータを解析手法ごとに用意していますし、 膨大な数の R のサンプルデータを簡単に検索して読み込めます。 また、できるだけ詳細に解説を付けてありますので、実際にデータを操作しながら統計を学んでいただくことが可能です。
Google Drive や One Drive のデータファイルを読み込めますので、ご自身のデータの解析して論文の原稿を書くこともできてしまいます!

インタラクティブな解析で理解が深まります
Reactive stat の名前の由来は
データの内容を常に確認しながら設定し、設定を変更するとリアルタイムにグラフなどが変化することが名称の由来です。
常にデータ内容を視覚的に把握しつつ解析を行えます
小さなヒストグラムなどで、しつこいほどにデータ内容を視覚的に示します。
統計処理においては、常にそのデータの性質、すなわち、カテゴリー変数なのか連続変数なのか、どのような分布をしているのかなどを把握しておく必要があります。
常にデータ内容を意識しつつ作業できますので、迷うことなく素早く正しい結果に到達できます。
すべての統計手法にデータと設定のサンプルを用意してあります
すべての統計手法のページには、 サンプルデータと設定の呼び出し ボタンが付いています。 これを押すと、典型的なサンプルデータと、そのデータに対する解析のための設定内容が読み込まれます。
その統計手法を初めて扱う場合でも、 どのような形式のデータが必要なのか、どのような形で結果が得られるのか、 サンプルを読み込んで実際に動かすころで理解が深まります。 そして、ご自身のデータをどう処理すればよいかがすぐに分かります。

信頼できる R の解析結果を AI に解説させて容易に理解できます
Reactive stat では、ほとんどの統計解析を R言語 (統計解析を主な目的とする専門的なシステム) を利用して行うことができます。
R は数多くの専門家が参画して作り上げられたシステムで、信頼性が高く、無料で利用できる素晴らしいものですが、なかなか敷居が高いです。 出力された解析結果も、英語で書いてあってわかりにくいです。
それを劇的に使いやすくしてくれたのが EZR ですが、インストールが必要だったり、やはり統計解析の初心者には難しいという声も聞かれます。
そこで、Reactive stat では、ブラウザでの簡単な操作で、インタラクティブに R による解析が行えるようにしてみました。 さらに、その解析結果を、AI に解説してもらう機能が付いています。
AI による解説には、そこで使われている統計手法の説明から、得られた結果の解釈、さらには学会発表や論文にどのように表現すればよいかまで含まれます。
論文や学会発表の準備が簡単になります
医療統計でよく使う統計手法を網羅しています
特に医療分野で頻繁に使われる統計手法を広くサポートし、また、医学論文で必要なグラフの作成が簡単に行えます。 今後、リクエストがあればさらに拡充してゆく計画です。
また、心理統計の領域で使われる手法も今後拡充してゆきます。
最新の R による解析結果が得られ、論文への記載が容易です
- 論文発表や学会発表において、「統計解析はRで行いました」と書くことができます。
- Rは通常、毎年2回 (4月と10月) バージョンアップされます。これらのリリースにはバグ修正などが含まれます。
- 解析ごとに、R 本体および使用されたすべてのライブラリのバージョンを表示します。
- 近年重要視されるようになった効果量の値の計算が多くの統計手法でサポートされています。
- 論文にどのように書けばよいか、AI が教えてくれます。
論文や学会発表で必要なサマリー表がすぐに作成できます
ほとんどの臨床系の論文で必要とされる、症例の背景因子の表が、あっという間に作成できます。 一つ一つの因子を統計解析し、その数値をまとめて表にするのは、意外と手間のかかるのもです。 これを、本当にあっという間に作成してくれます。 ぜひお試しください。
ドラッグ&ドロップで項目を入れ替えたり、統計処理がパラメトリックとノンパラメトリックから選べたり、徹底的に使いやすさを追求しています。 使いこなしていただけると嬉しいです。
p値まで含んだ表が出力されますので、学会発表くらいなら統計処理がこの機能だけで済んでしまう場合もしばしばあります。
本当に「あっという間に」思い通りのサマリー表が作成できてしまいます!
")
多彩なチャートを簡単に作成できます
多く用いられるチャートを簡単に作成できるよう、チャート作成機能を充実させました。
対象ユーザー
- 統計学には興味は無いが学会発表があるのでちゃちゃっとデータ処理を済ませたい方
- 実際のデータを触りながら統計を学びたい初心者
- 手持ちのデータを探索的に把握したい研究者
などなど、(統計学者以外の) あらゆる方が対象です。
統計結果のグラフは、設定の変更をリアルタイムに反映しますから、その理解が簡単です。 上の例にも示すように、ROC曲線における閾値の変化で、感度や特異度がどう変わるのか、実際にサンプルデータで試してみることで、その原理まで理解が深まります。
また、常にデータの内容を視覚的に示しつつ設定を進めてゆくという基本コンセプトですので、どうしていいかわからない迷子になってしまうことがありません。
Reactive stat により、統計嫌いが少しでも減ることを願っています。 そして、皆様の貴重な研究成果の発表のお手伝いができると嬉しいです。
企業担当者の連絡先を閲覧するには
会員登録を行い、ログインしてください。






