 デジタル
デジタル
 ゲーム・ホビー
ゲーム・ホビー
 システム・通信
システム・通信
 観光・レジャー
観光・レジャー
 エンタメ
エンタメ
 スポーツ・アウトドア
スポーツ・アウトドア
 自動車・バイク
自動車・バイク
 ホーム
ホーム
 ファッション
ファッション
 食・グルメ
食・グルメ
 美容・健康
美容・健康
 ライフスタイル
ライフスタイル
 金融・保険
金融・保険
 広告・宣伝
広告・宣伝
 交通・物流
交通・物流
 エネルギー・環境
エネルギー・環境
 自治体など
自治体など
無料のウェブ統計ソフト Reactive stat で行う傾向スコアマッチングがさらにわかりやすくなりました
エミュイン合同会社
2024.09.15 15:19
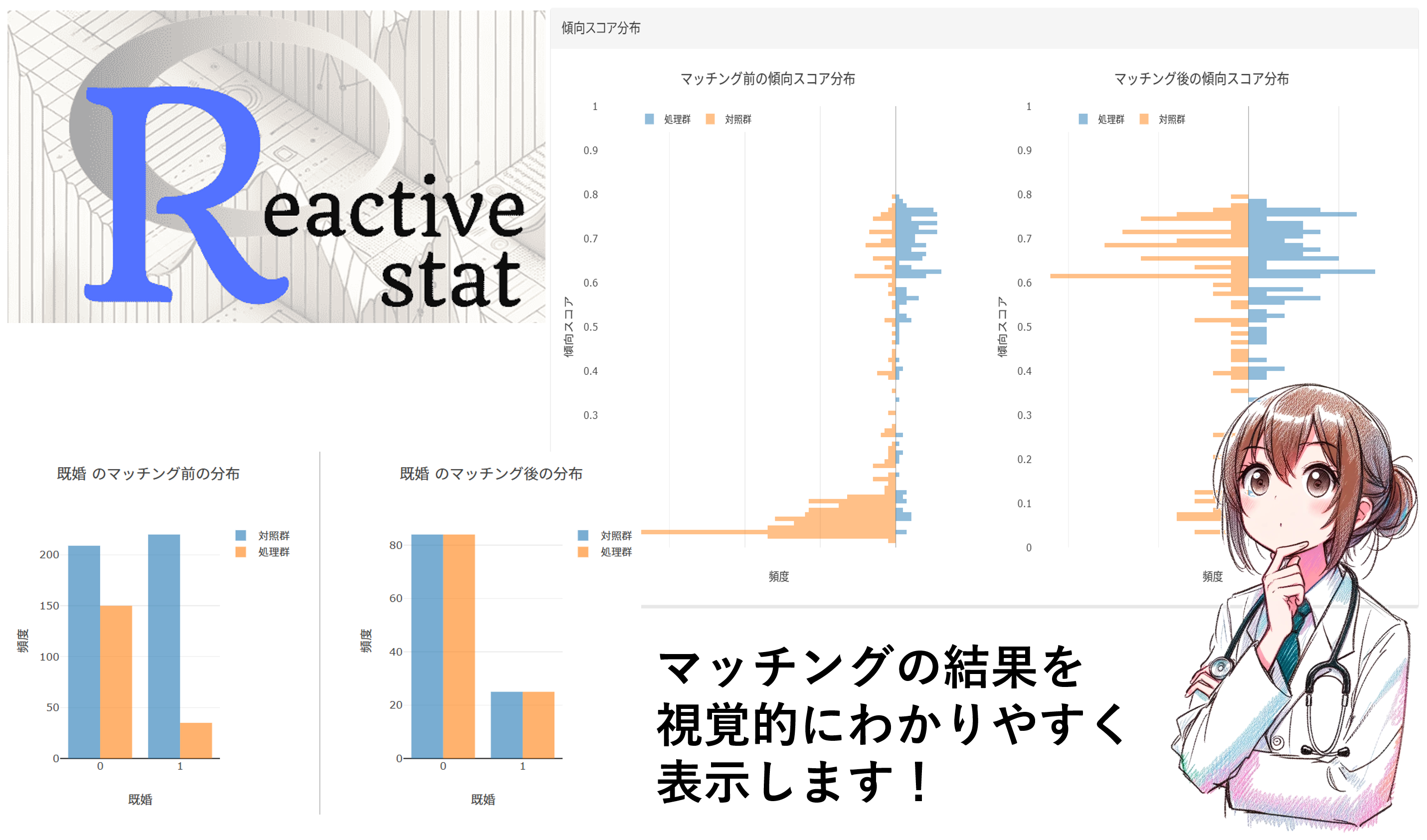
マッチング後の傾向スコアの分布や共変量を視覚的に確認できますので、敷居が高いと思われている傾向スコアマッチングの手法の理解が進みます!
Reactive stat は、ブラウザだけで使える無料統計ソフトです。信頼性の高い R で統計解析し、その結果を AI が解説します。傾向スコアマッチング (propensity score matching; PSM) は、観察データから因果関係を推定する統計手法です。 医学研究などで、ランダム化されていないデータにおいて、治療群と非治療群間のバイアスを調整します。 各参加者の治療受領の確率 (傾向スコア) を推定し、スコアが似ている被験者同士をマッチングします。 計画段階から共変量のバイアスを小さくする方法として、ランダム化 (無作為化) 比較試験があります。 しかし、ランダム化ができない観察研究や、遡及的研究 (retrospective study) では、得られたデータをそのまま利用すると、共変量のバイアスが問題となります。
傾向スコアマッチング (propensity score matching; PSM) は、観察データから因果関係を推定する統計手法です
特に医療統計の領域で使われることとが非常に多くなってきていますが、なんだか難しそうで敬遠している方も多いのではないでしょうか?
実は意外と根本を理解できれば比較的容易に適用可能です。特に遡及的なデータから説得力を持って結論するためには非常に強力なツールとなります。

医学研究などで、ランダム化されていないデータにおいて、治療群と非治療群間のバイアスを調整します。 各参加者の治療受領の確率 (傾向スコア) を推定し、スコアが似ている被験者同士をマッチングします。
計画段階から共変量のバイアスを小さくする方法として、ランダム化 (無作為化) 比較試験があります。 しかし、ランダム化ができない観察研究や、遡及的研究 (retrospective study) では、得られたデータをそのまま利用すると、共変量のバイアスが問題となります。
例えば、癌のステージII の患者さんの平均年齢が90歳で、ステージIIIの平均年齢が70歳では、単純に予後を比較してもその解釈は困難で、誤った結論につながります。 そのため、多変量解析や、ここで提供する傾向スコアマッチングを利用します。
利点
- 観察データにおいて治療群とコントロール群間の共変量のバランスを改善し、選択バイアスを減らせます。
- 多変量解析では、モデルが共変量の影響を適切に調整しているかが不明確な場合があります。誤った統計的モデルは誤った結果につながります。しかし、傾向スコアマッチングでは、治療群とコントロール群間で共変量がより均等になるように個体をマッチングします。これにより、治療効果の推定が、共変量の影響がバランスされた状態で行われるため、より正確になる可能性があります。
- マッチング後の解析が容易です。
欠点
- 適切なマッチングを見つけるのが困難な場合があります。
- マッチングプロセスにおいて「利用できないデータ」、すなわち、適切なマッチが見つからないために分析から除外されるデータが発生します。これは特に、マッチング対象の個体が少ない場合や、特定の特性を持つ個体が少ない場合に顕著です。その結果、分析対象のサンプルサイズが減少し、結果の一般化や統計的な力に影響を与える可能性があります。
使用方法
応答変数の選択
応答変数には、研究で比較する対象 (例: 治療の有無) を指定します。 この変数は2値 (バイナリ) である必要がありますが、3値以上の場合には、そのうちの一つを処理群に指定し、それ以外は自動的にコントロールに割り当てます。
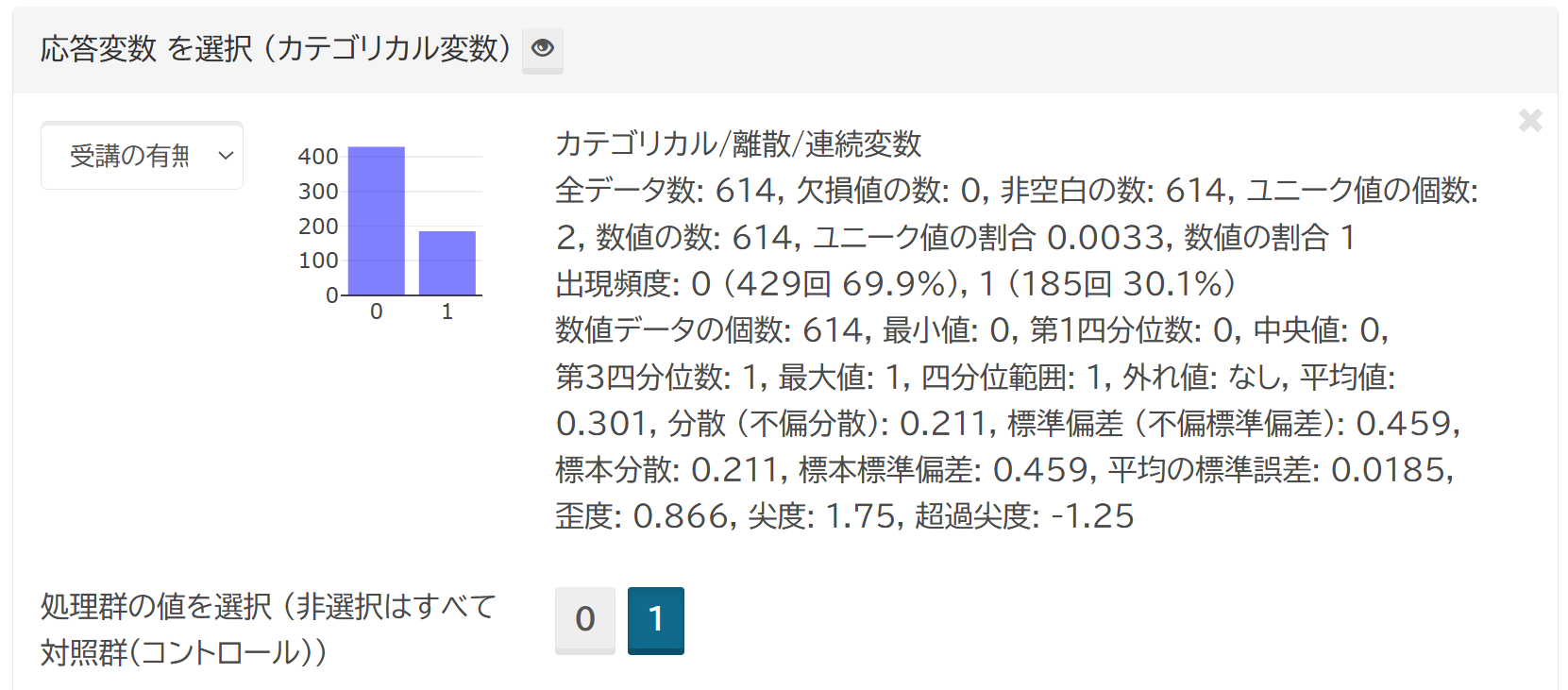
カラムを選択すると、そのデータがミニヒストグラムで表示され、基礎統計量も表示されますので、データの内容を把握しながら解析を進めることができます。
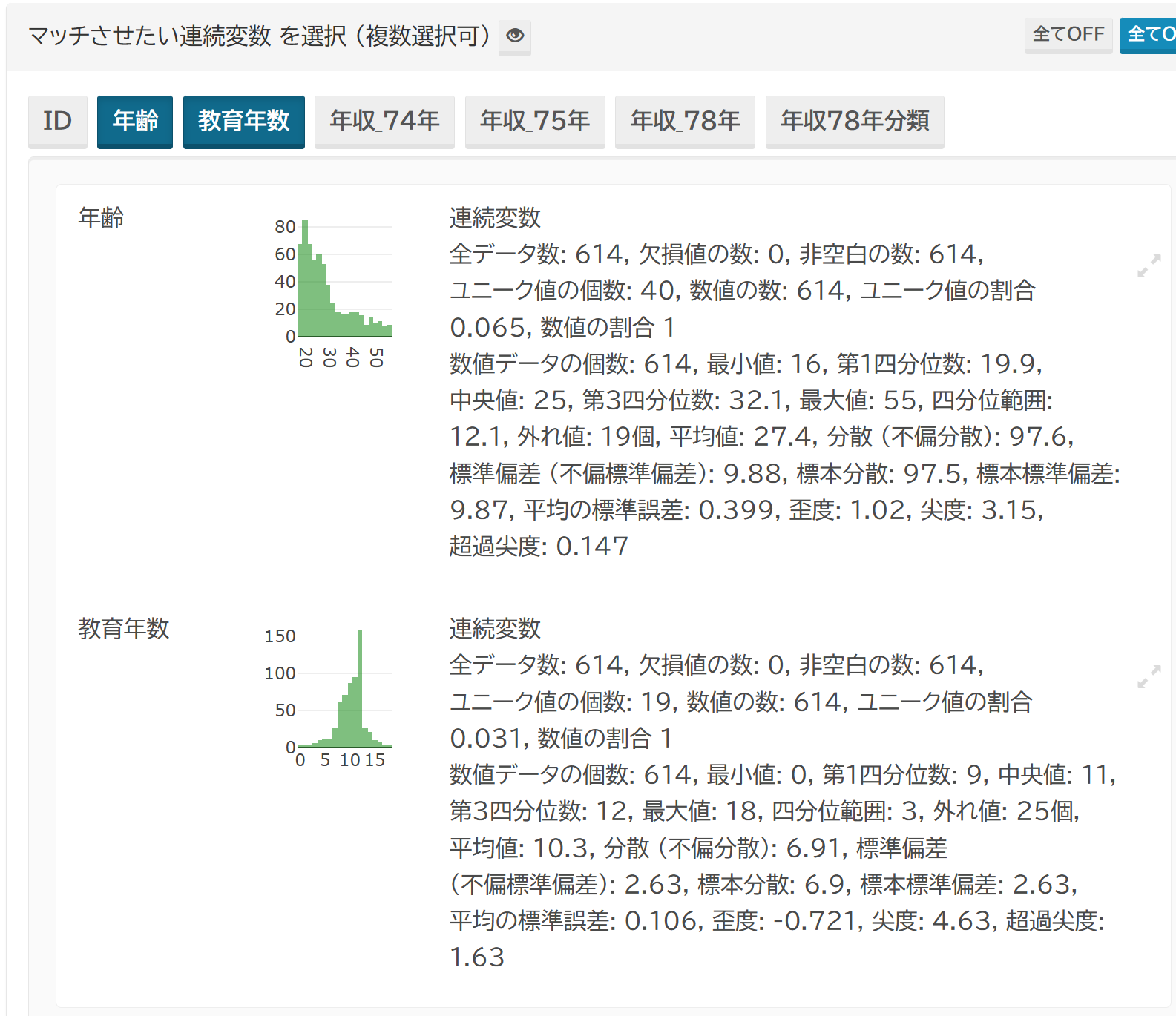
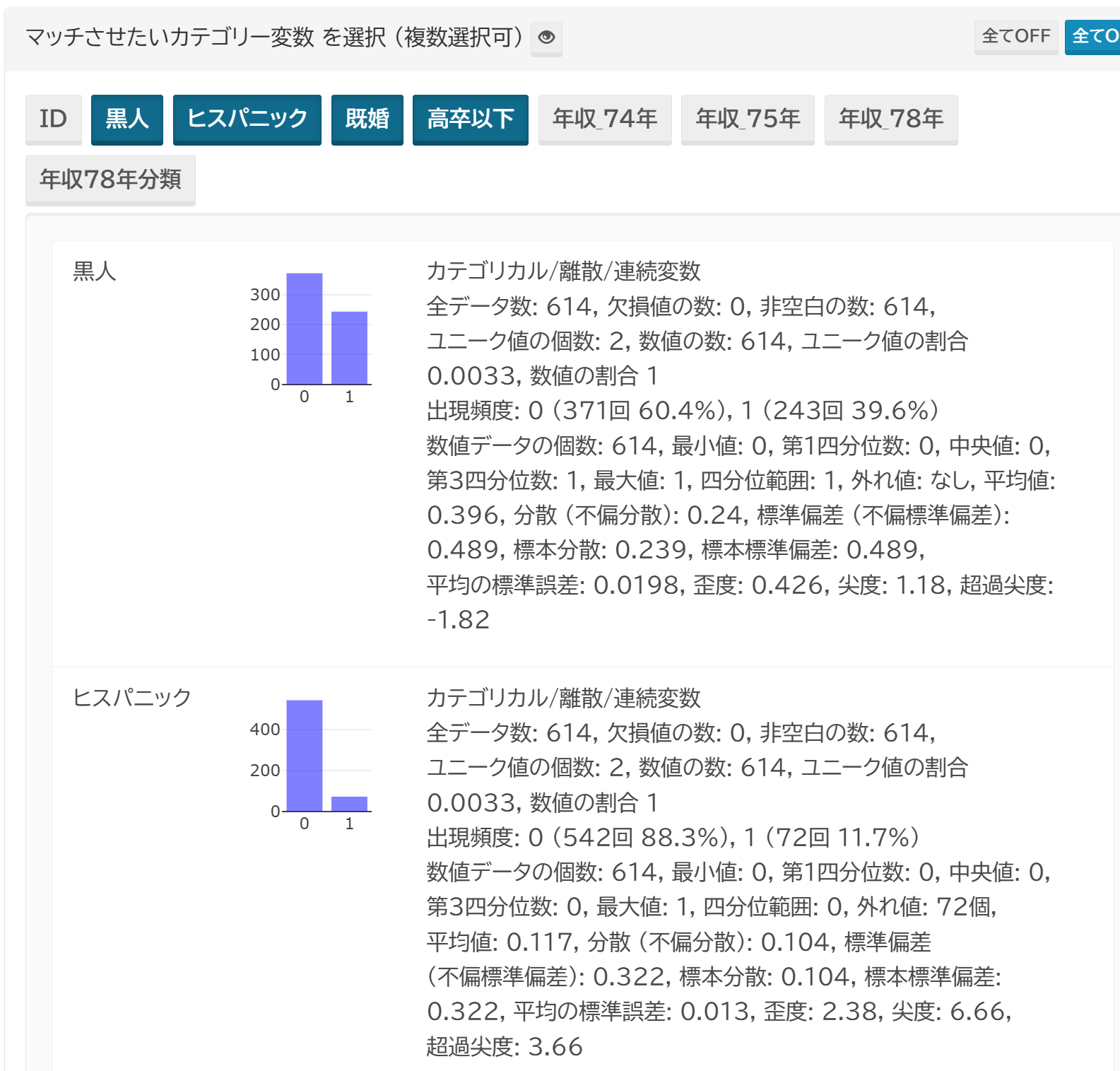
マッチさせたい変数の選択
連続的な特性や測定値 (例: 年齢、血圧) と、カテゴリー (離散) 変数 (例: 性別、喫煙歴) は、扱いが異なりますので、別々に指定します。
このとき、数値で表されたカテゴリー変数については、順序がある場合には連続変数として選択することができますが、数値の間隔は一定であることを前提として解析します。 カテゴリー変数として選択した場合には、数値の大小関係は無視され、単なるラベルとして扱われます。
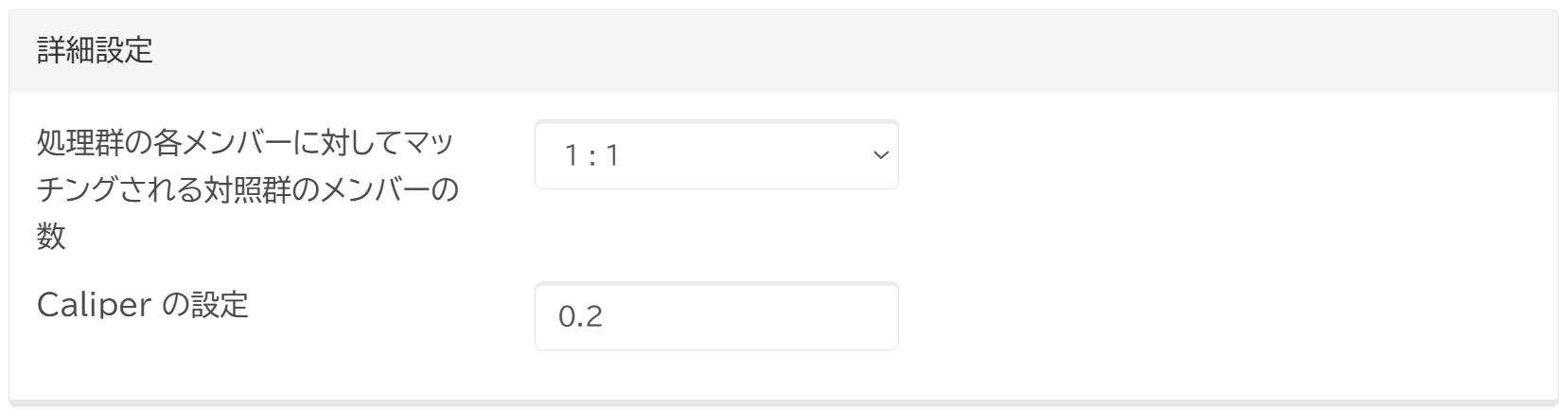
処理群と対照群のマッチング比率の設定
処理群の各メンバーに対してマッチングされる対照群メンバーの数を設定します。デフォルトは1:2です。
Caliperの設定
傾向スコアの差の最大許容値を設定します。 デフォルトは0.2です。 Caliper を設定することで、マッチングされるメンバー間の類似性を制御します。
Caliper を小さくすると、マッチングされる個体間の類似性は高まりますが、一方でマッチングできる個体の数が減少します。 その結果、特にサンプルサイズが小さい場合や傾向スコアの分布に大きな違いがある場合、マッチング対象となる個体が不足することがあります。 これは、分析の一般化可能性や統計的な力に影響を与える可能性があるため、Caliperの設定は慎重に行う必要があります。
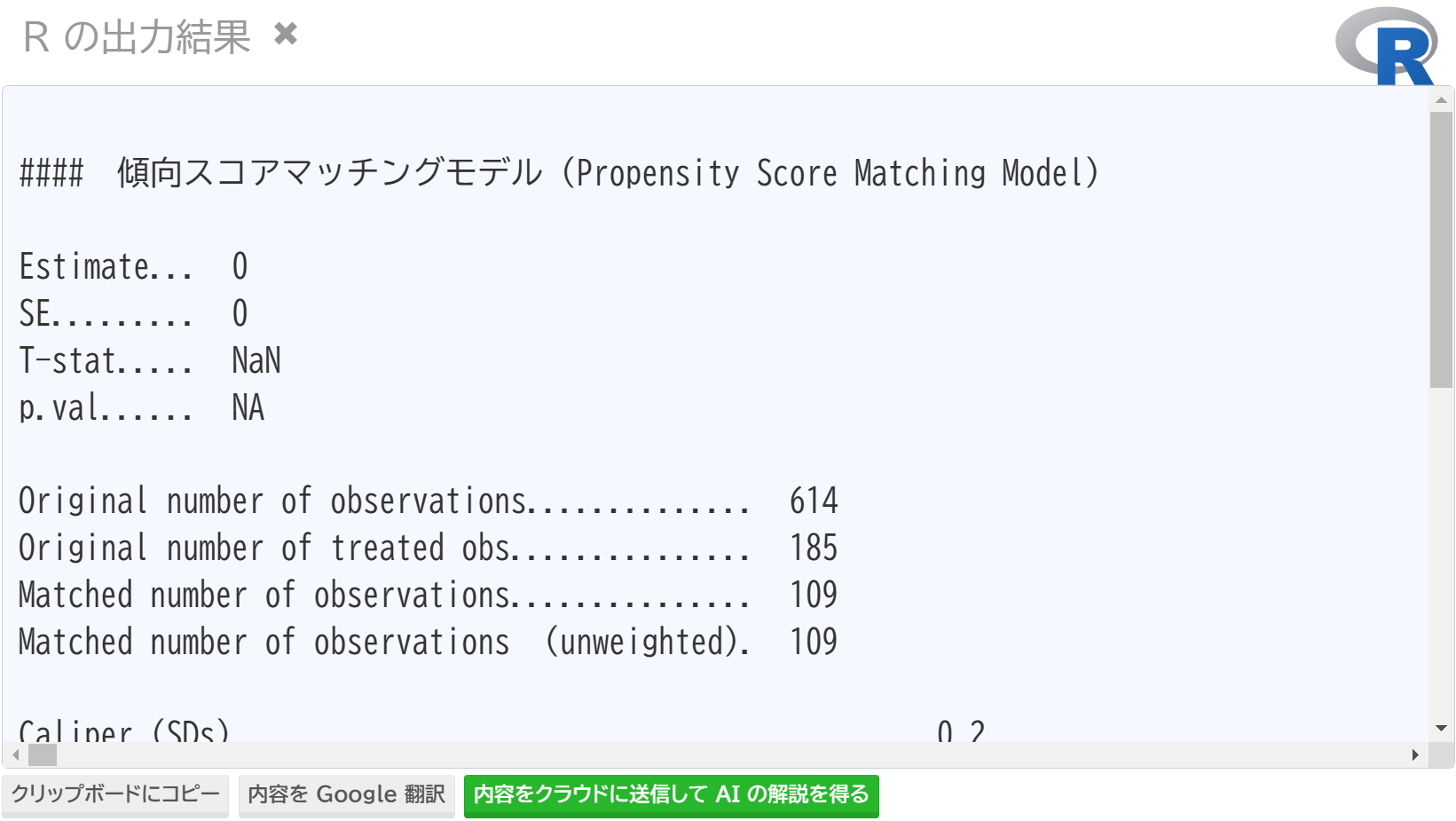
結果
傾向スコアマッチングの計算自体は、クラウドの R で実行します。そのため、信頼性の高い結果が得られます。
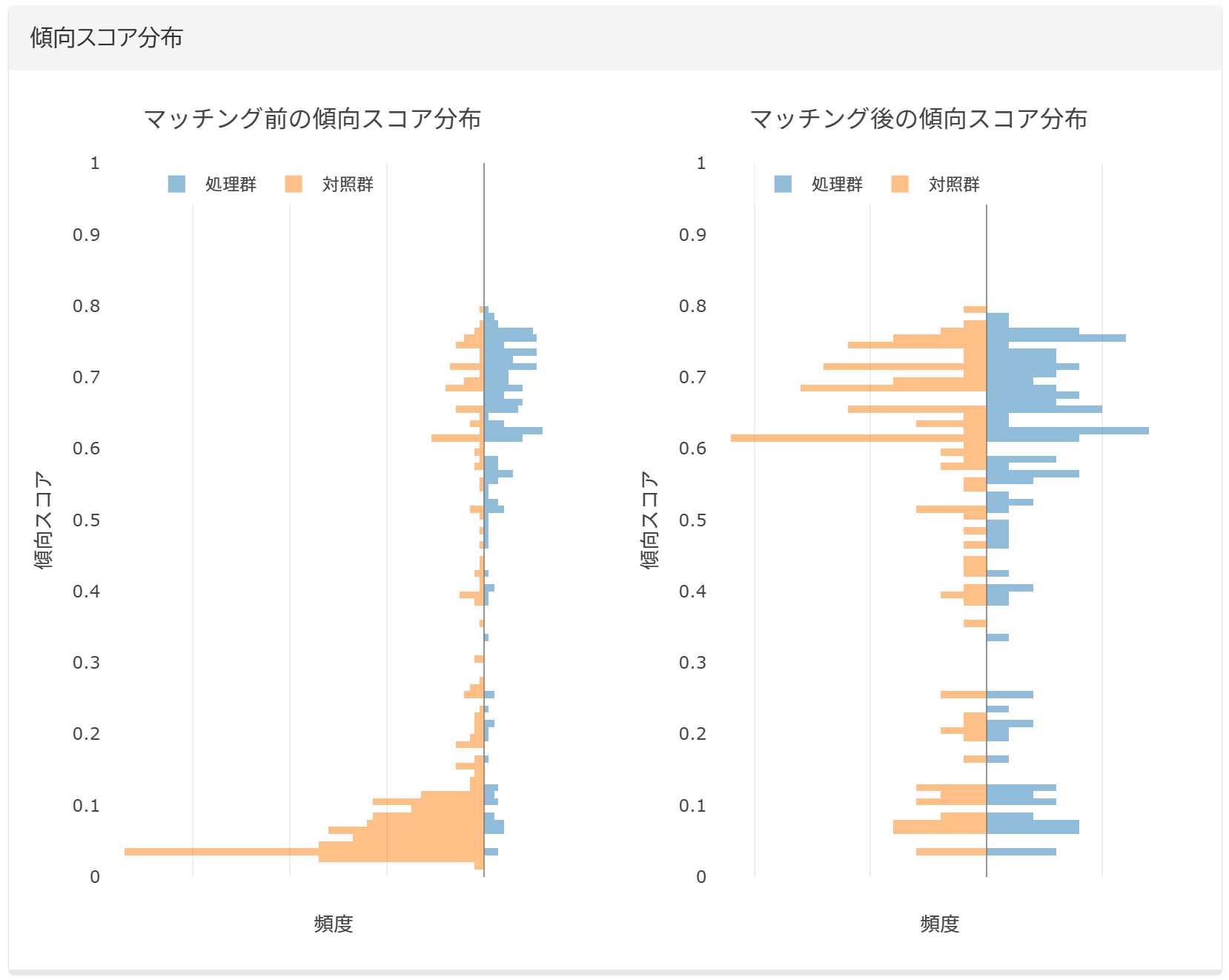
マッチング結果の表示
傾向スコアによるマッチングの結果は、視覚的にわかりやすく表示します。わざわざ確認のために別の操作を行う必要はありません。
慣れた方には、ちょっと表示が冗長すぎると感じられるかもしれませんが、むしろ傾向スコアマッチングの処理に不慣れなユーザーや、これから勉強して応用したいというユーザーに理解を深めていただくことをひとつの目的としていますので、ご理解いただければと思います。
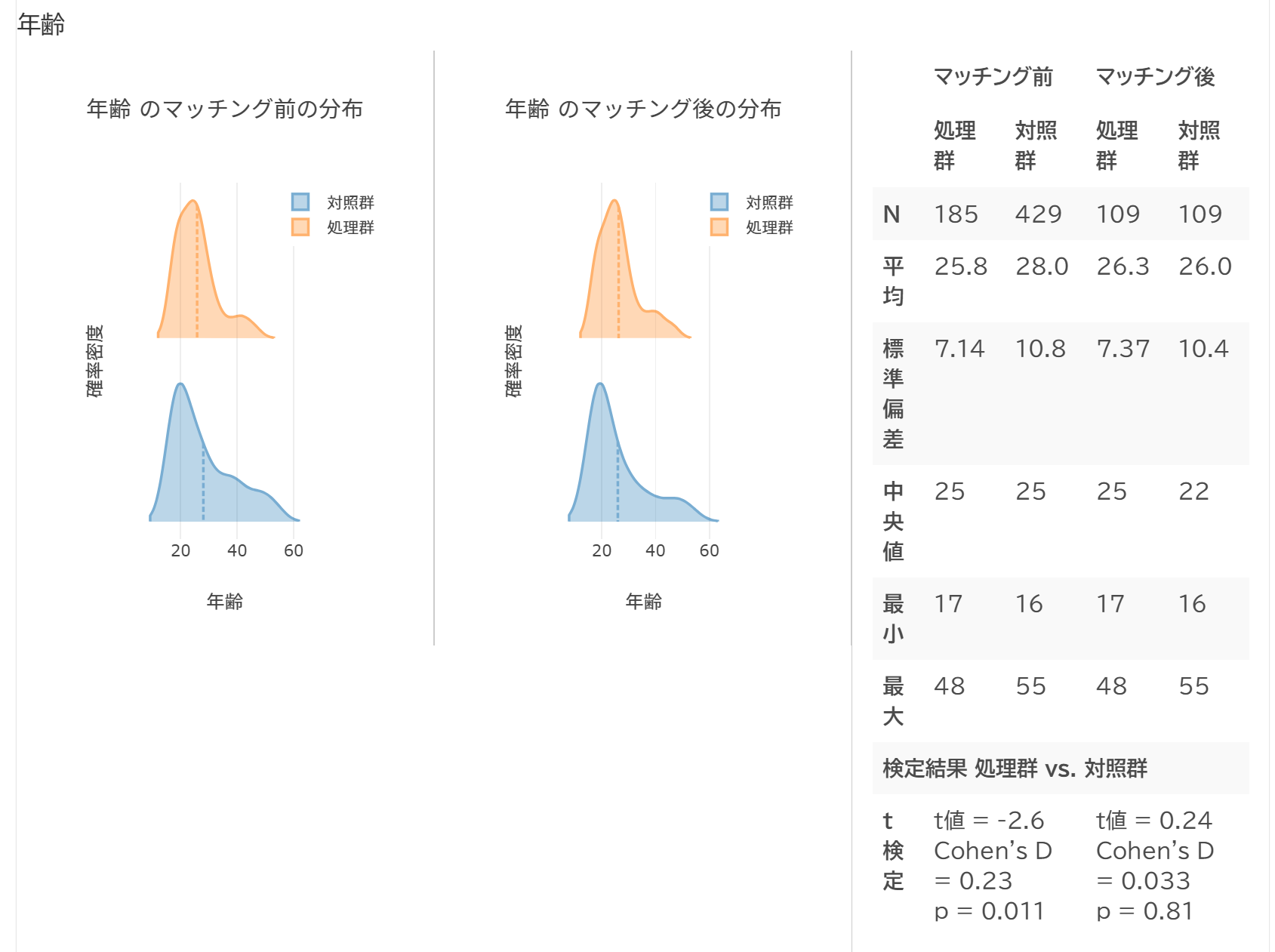
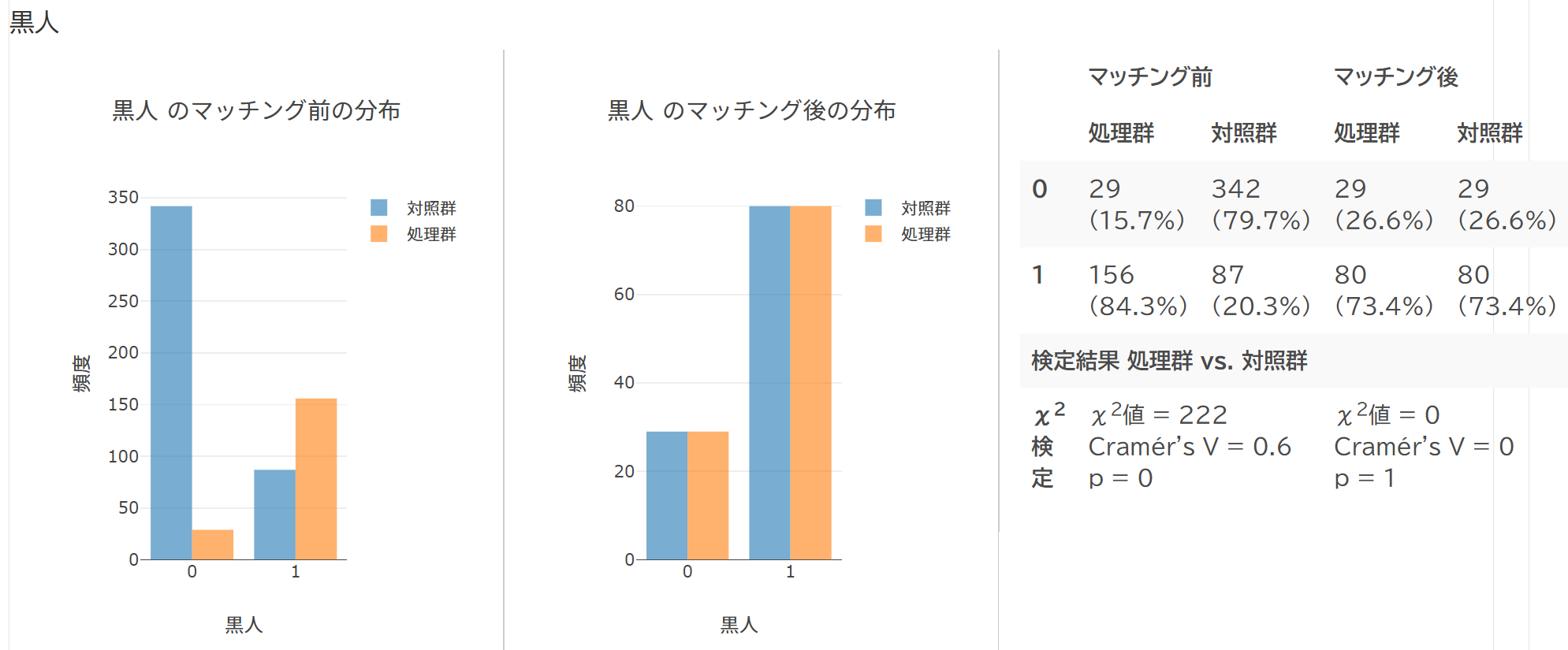
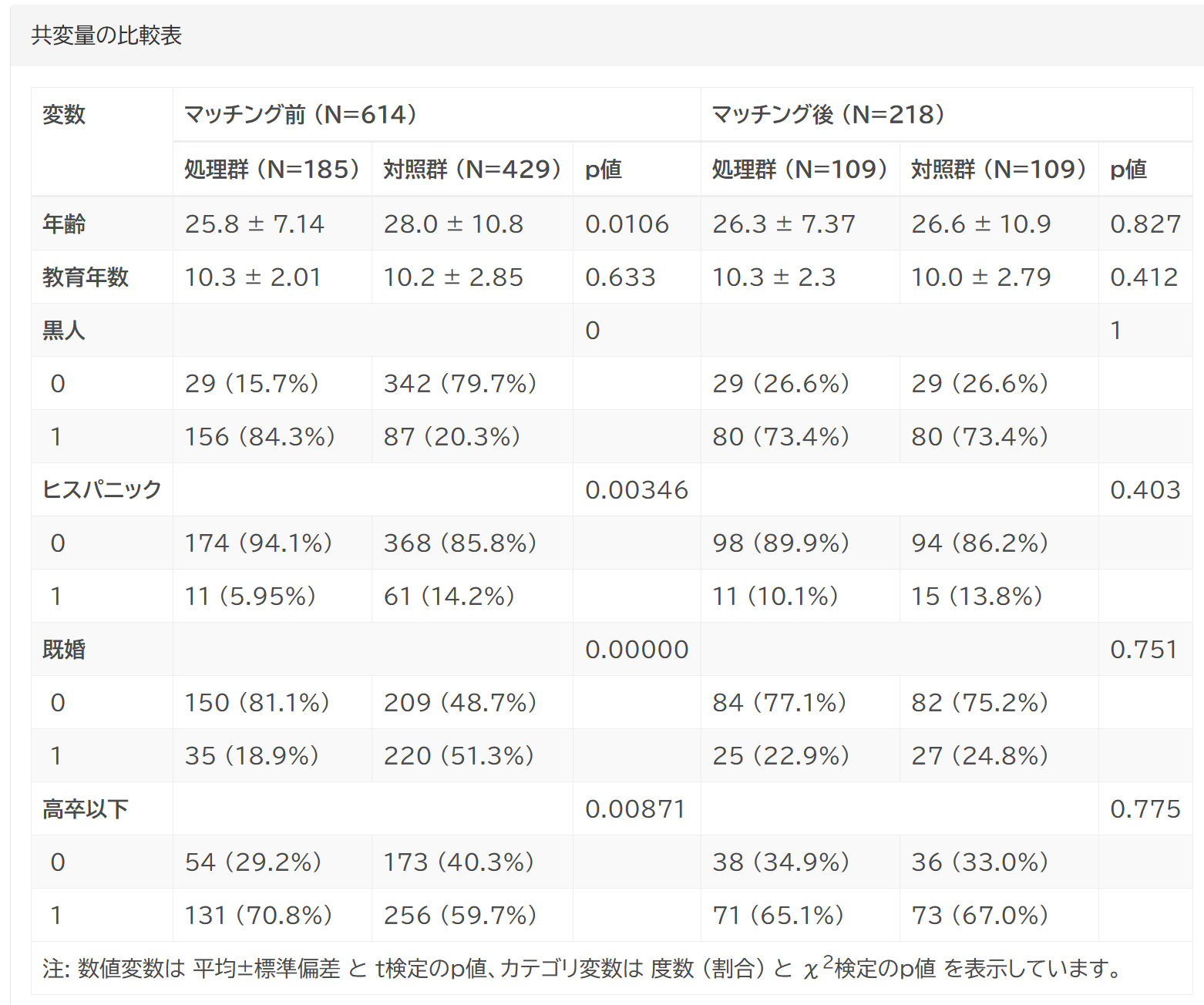
マッチング処理後
マッチングできたら、その情報を以下の2つの特殊カラムに追加できます。
- __matched_pairs__: マッチング対象となった行には、対応する通し番号が入ります。マッチング対象とならなかった行には、空白が入ります。
- __propensity_scores__: 傾向スコア の値です。
これらのカラムは、通常の統計処理の対象にはなりません。 引き続いて マッチさせたサンプルの 比率の比較(Mantel-Haenzel検定)、 比率の多変量解析(条件付ロジスティック回帰)、 生存率の多変量解析(層別化比例ハザード回帰) を行う際に、内部的に使用されます。
Reactive stat は、ブラウザだけで使える無料統計ソフトです。信頼性の高い R で統計解析し、その結果を AI が解説します!

ブラウザとデータファイルがあれば、すぐに解析できます
- マニュアル本は要りません。
- すべての統計手法のページには、利用に必要な解説が載っていますし、必要な情報へのリンクも用意してあります。
- PCにソフトウェアをインストールする必要はありません。
- 信頼性の高い R での結果が得られます。
- ウェブアプリで結果を得たあとに、そのデータを外部の R サーバーに送信し、その実行結果を得ることができます。
- 外部の R サーバーに送信されるデータは、セキュリティを考慮し、数値計算に必要な最小限のセットとしています。また、送信前に内容を確認できます。自動的に送信されることはありません。
- 常に最新バージョンのRを利用できます。
- 結果がリアルタイムに反映されるウェブアプリですので、統計解析に不慣れな場合でも試行錯誤が容易です。
- データの内容を常に把握しながら作業が行えるように工夫してありますので、どうしたらいいかわからない、という状況に陥ることがありません。
- 出力されるグラフはインタラクティブな高機能なものです。
- データファイルを読み込んで利用できます。
- CSV 形式データファイルおよびエクセルファイルに対応
- データファイルはブラウザ内部に読み込まれるだけで外部には送信されませんので、セキュリティの問題はありません。
- 日本語のデータファイルを扱うことができます
- 海外製のアプリですと、カラム名が日本語だと受け付けられないなどの制約がしばしばありますが、Reactive stat にはそのような制限はありません。
企業担当者の連絡先を閲覧するには
会員登録を行い、ログインしてください。






